Blog Stop Patching on a Schedule. Start Patching on the Clock.
By Jeremy Nelson / 27 Jun 2026 / Topics: Security services , Managed security , Generative AI , Cybersecurity

Key takeaways
- Exploit windows have collapsed from days to hours, so a breach is now the likely outcome — not the rare one.
- A breach is itself a production outage; the only real choice is whether the disruption is planned and on your terms, or unplanned and malicious on theirs.
- Treating critical vulnerabilities as incidents (measured by mean time to remediation, not percentage of assets covered) replaces the calendar-based patch cycle.
- Responding in real time to the small subset of genuinely exploitable vulnerabilities actually reduces operational risk versus batching patches.
- The shift is organizational, not technological: it demands high-availability architecture and buy-in well beyond the security team.
Exploits now move in hours, not days. The question isn’t whether you’ll be disrupted — it’s whether it happens on your terms or theirs.
A few weeks ago, I was in the middle of a meeting when my laptop decided it was done waiting for me. I’d pushed off the same patch update one too many times, and right there, mid-sentence, it shut down. No more “remind me later.” No option to delay.
And here’s the thing, I couldn’t even be mad about it. I grabbed my phone, dialed back into the meeting, and kept going. Because that policy (the one that just interrupted my call) is the same one I’ve been telling security leaders they need to adopt: forcing disruption on your own terms, not someone else’s.
Patching ‘on the clock’ means treating critical vulnerabilities like active incidents, measured in hours to respond, not prescribed days on a calendar.
And if I’m going to ask our clients to rethink how they patch, I’d better be living it myself.
So, here’s how I’ve been framing this with security leaders.
The slider in my head
I came up with this picture during a lunch conversation with a security leader at Cisco Live, and I haven’t been able to put it down since. Imagine a slider. On one end is operational impact: the risk of disrupting your business. On the other end is a security incident: the risk of getting breached. Every organization is sitting somewhere on that bar whether they realize it or not, and where they sit tells you everything about how they think about risk.
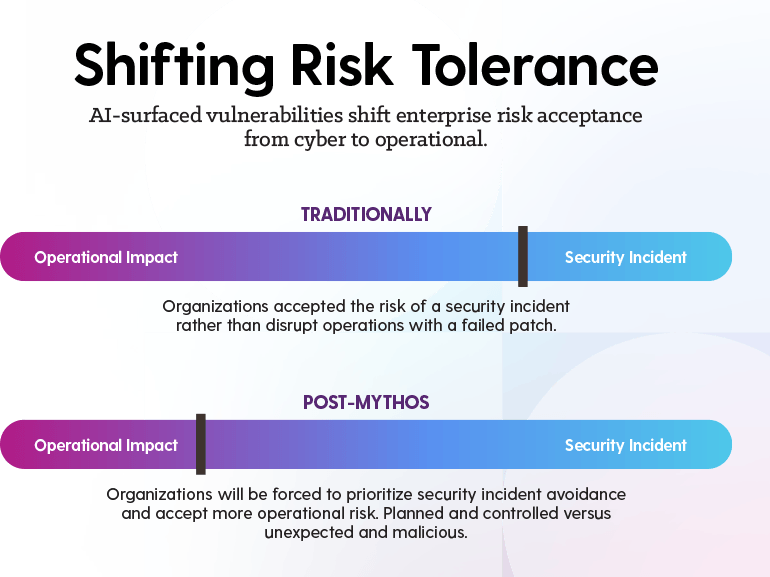
Here’s what most organizations have been signaling for years. When you run a 90-day patch cycle (and I’ll be honest, that was our cadence at Insight not that long ago), you are making a bet. You’re saying, “I’d rather roll the dice on a cybersecurity incident than risk taking down production to apply a patch.” You’ve planted your slider firmly on the side of protecting operations. You feel like a breach is the less likely outcome, so you optimize against the disruption you can see coming.
I understand that instinct completely. We love our processes. We love our change windows, our CAB reviews, our controls; they exist to keep us safe and IT operations predictable. But Mythos — and other frontier AI models like it — have quietly shifted the odds on that bet, and a lot of leaders haven’t responded and moved their risk slider yet.
The part everyone misses
Here’s what changed my own thinking. When the window between a vulnerability being disclosed and an exploit landing in the wild collapses from days to hours (and at some point in the not-too-distant future — minutes), the breach stops being the unlikely outcome. It becomes the imminent one.
And, this is the piece I really want you to sit with, a breach is also a production outage. You don’t get to avoid the disruption by not patching. You just trade one kind for another.
When you patch on your terms, the disruption is planned and controlled. You’ve scheduled it. You’ve got your people on standby. You’ve got rollback tools ready. If something goes sideways, you fix it and move on.
When you get breached, you still have an outage, but now it’s unplanned. It’s unexpected, it hits at 2 a.m. when you don’t have the staff you need, and it’s malicious. The person who caused it has a vested interest in keeping you down, not helping you get back up. That’s the whole reframe right there: planned and controlled versus unexpected and malicious.
You’re not choosing whether to be disrupted anymore. You’re only choosing whose terms it happens on.
Two modes, same vulnerability
This is why I’ve started talking about patching as an incident rather than a maintenance task. Same CVE, completely different posture.

In the maintenance model, the question we ask is “Will this patch break production?” We measure success by the percentage of assets we’ve covered, and the clock runs in weeks or months. In the incident model, the question flips to “What’s the blast radius if we don’t patch this?” We measure success by mean time to remediation, and the clock runs in hours. When exploitation takes hours, a monthly maintenance window isn’t a process anymore — it’s a liability.
Now we’re talking about deploying patches through the same type of workflow you’d expect from a traditional cybersecurity incident: detect, triage, contain, remediate, validate. We capture the disclosure through continuous threat exposure management, find everywhere it lives across the estate, use machine learning to score how likely it is to actually be exploited in your specific environment, and validate that with continuous penetration testing. If it’s a high to critical vulnerability, an SLA clock starts and our response teams are in immediate motion.
This isn’t about patching everything the moment it’s disclosed. It’s about finding the small subset of vulnerabilities that pose real, exploitable risk in your environment, and treating those with incident-level urgency.
So what does this look like on a Tuesday morning?
Instead of waiting for the next patch cycle, a critical externally exposed vulnerability triggers an immediate workflow: security flags it, validates exposure, and initiates patching within hours, just as you would with an active incident.
The counterintuitive win
Now, if you’re an operations leader, your alarm is going off: more frequent patching means more disruption, right?
Actually, it’s the opposite, and this is the argument I want CISOs to take to their operations and business partners. One of the biggest reasons patch windows blow up is that we let patches queue, then push dozens of them into dozens of subsystems all at once. When you shift to responding in real-time, you’re patching one affected module, on its own. The odds of a nasty downstream surprise drop dramatically. You’re taking smaller, more controlled, more targeted bites, and reducing operational risk in the process.
This is a change in how you operate
I won’t pretend the technology is the hard part. It isn’t. The hard part is organizational. You have to be willing to break the mold of how you’ve always approached patching, and you have to build genuine high availability into your systems, because you can’t run big monolithic apps under this model without risking that critical application every single day. That’s a different way of thinking about architecture, and it’s a conversation that has to reach well beyond the security team.
I’ll leave you with the same question I keep coming back to. You are going to absorb some disruption; that part isn’t optional anymore. The only thing you get to decide is whether it’s planned and on your terms, or unplanned and on theirs.
At Insight, we’ve made ourselves client zero for this radical change in approach to patching IT systems. We faced the same existential shift everyone else is facing, rebuilt how we approach security and IT operations around it, and then brought it to our clients. Because it doesn’t really matter who has access to Mythos. It exists. And it exists with the release of similarly capable models on the horizon, some of which aren’t being developed by the “good guys.”
What matters is whether you’ve recognized that the way you defend your business has fundamentally changed — and that you move your slider before someone moves it for you.
Patch on your terms, not an attacker's. Explore Insight's Managed Exposure Defense and turn your biggest vulnerabilities into incidents you control.
About the Authors:

Jeremy Nelson
Chief Information Security Officer, North America, Insight
Jeremy has over 25 years of experience in the information systems industry with a specialization in Cybersecurity. Over his career Jeremy has held a diverse range of roles and positions encompassing help desk technician, technical engineer, security auditor, Enterprise Architect, and a P&L owner. In his current role as Chief Information Security Officer for North America, Jeremy is responsible for the security of Insight's full portfolio of client facing services with the guiding principle of ensuring that "our clients should never be less secure because they chose to partner with Insight."
 Monthly perspectives from global tech leaders.
Monthly perspectives from global tech leaders.



