Tech tutorials Azure Near-Real-time Replication
By Insight Editor / 26 May 2016 , Updated on 16 May 2019 / Topics: Microsoft Azure
By Insight Editor / 26 May 2016 , Updated on 16 May 2019 / Topics: Microsoft Azure
One of the wonderful things about the cloud is all the tools and architectural options it provides. One of the most difficult things is choosing the tool or architecture to use. Azure provides out-of-the-box alternatives to replicate data across data centers for SQL Azure, Storage Tables/Blobs and, more recently, DocumentDB. However, these come at a premium price and may not provide the efficiency you require.
All of the out-of-the-box Azure replication solutions consist of a single read/write data store (source of truth) with geographically redundant read-only data stores. This is a prudent approach from a data consistency standpoint, but not the most efficient if you’re attempting to post data from halfway around the world.
Another alternative is to roll your own replication using Azure Service Bus as the communication vehicle to obtain near-real-time, bidirectional data replication with active read/write data stores in each data center.
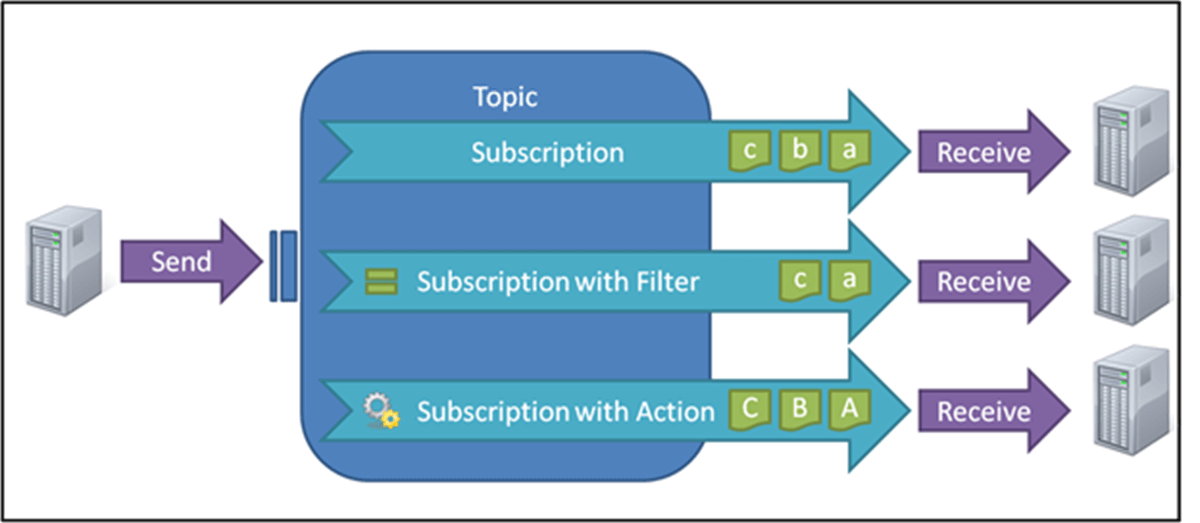
Service Bus topics and subscriptions provide a rich and efficient mechanism to move data. Additionally, when bringing a new data center online, it makes replication as simple as deploying your solution to the new data center, bulk copying your data and then adding a subscription to the replication topics in the other data centers.
In one project I worked on, there were two primary applications: a configuration tool and an end-user application. The configuration tool was critical across all data centers but was managed by only a handful of inpiduals in a central location. Those inpiduals were tasked with a specific area with very little potential for data conflicts.
The configuration component was a good fit for our replication solution. The processing component was more complex. While some of the application required strong data concurrency for part of its functionality, it posed little risk of conflict as it collected new user responses. The decision was made to separate the contentious data from the well-behaved, nonconflict, sensitive data and to replicate the nonconflict data using the same approach.
As with many cloud applications, a variety of data stores were used, including SQL Azure, DocumentDB, Table and Blob Storage. Base components were created for each of these data sources through which all data flowed.
For SQL Azure, we created a layer on top of Entity Framework. For DocumentDB and Storage Tables and Blobs, we used wrappers on top of .NET Azure components for DocumentDB and Storage. Upon successful writing of data, these base components wrote a JSON serialization of the write transaction to a Service Bus topic hosted within its own region without further processing.
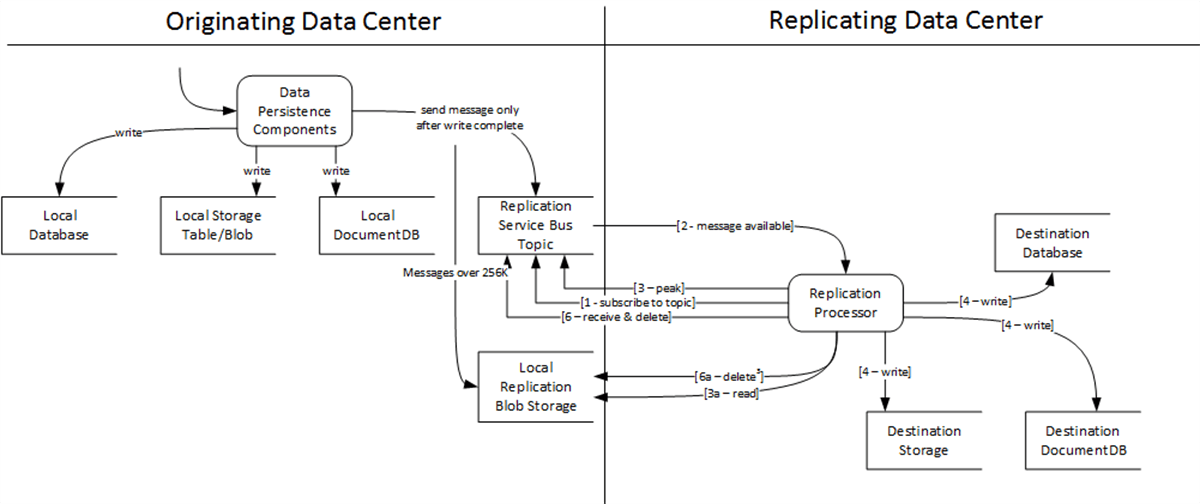
Developers implemented data repositories to meet their requirements using the base data persistence components to handle data Create, Read, Update and Delete (CRUD) operations. These data components then wrote the required replication information to the Service Bus topic without additional custom coding on their part. The diagram above follows the flow of data as it’s received in the data persistence component to the replicating data center’s data stores.
The data persistence components create a Service Bus Brokered Message for each data write containing a JSON serialized representation of the written data objects to the local data center, along with metadata describing their source object type and data store destination (SQL, DocumentDB, Storage). It then sends the message to its local data center’s Service Bus “replication” topic.
We chose an Azure App WebJob to host our replication processors in each data center. This just as easily could have been created to run within an Azure Cloud Service. Our choice was based on how quickly it could start after a fresh deployment and the “cloudy” (pun intended) future of Azure Cloud Services.
Upon startup, each data center’s replication processor reads its configuration data to determine the data center in which it was running and pull metadata on the other data centers with potential to write data. It then subscribed to the replication topic of each of these other data centers and, voila, began to receive and process data write messages from the other data centers.
WARNING: The solution outlined in this article is not a panacea to all of your near-real-time replication needs. It works best with data that’s written once without contention, or written by one source in sequence. If data consistency is paramount (i.e., nuclear reactor monitoring or drug dispensing), consider using a tried and extensively tested replication solution. This solution works great where data contention within your application is nonexistent or very minimal. If speed is your number one goal regardless of potential consistency problems, be prepared to handle data contention.
Advertisement